Image by kalhh from Pixabay
The article advocates for a more comprehensive evaluation method for Large Language Models (LLMs) by combining traditional automated metrics (BLEU, ROUGE, and Perplexity) with structured human feedback. It highlights the limitations of standard evaluation techniques while emphasizing the critical role of human assessments in determining contextual relevance, accuracy, and ethical appropriateness. Through detailed methodologies, practical implementation examples, and real-world case studies, the article illustrates how a holistic evaluation strategy can enhance LLM reliability, better align model performance with user expectations, and support responsible AI development.
The artificial intelligence application?domain underwent a?fundamental transformation because?of Large Language Models?(LLMs), including GPT-4, Claude, Gemini, and?other models. The?extensive use of?these models requires complete?evaluation through comprehensive assessment?methods. The evaluation?of these models?depends mainly on automated?metrics, which include?BLEU, ROUGE, METEOR, and?Perplexity. Research findings?demonstrate that automated?evaluation metrics fail to accurately predict user?satisfaction and model?effectiveness. A complete?evaluation framework requires the?combination of human?feedback with traditional metrics for assessment. This?paper demonstrates a?complete method to?evaluate LLM performance by?merging quantitative metrics?with human feedback assessment.?This paper examines?existing evaluation method?restrictions while explaining human?feedback value and?presents integration approaches with practical examples?and code illustrations.
The traditional metrics served?as standardized benchmarks?for earlier NLP systems,?yet they do not measure the?semantic depth, contextual appropriateness, and?creative capabilities that define?modern LLMs. Traditional metrics for evaluating LLMs mainly include:
The?evaluation metrics provide?useful information, yet they?have several drawbacks:
The evaluation metrics of?LLM—BLEU, ROUGE, perplexity,?and accuracy—were developed for specific?NLP tasks but?fail to meet?the requirements of contemporary?language models. The?IBM BLEU scores demonstrate a?weak relationship with?human assessment (0.3-0.4 for creative tasks), and ROUGE?correlation ranges from ?0.4-0.6 based on?task complexity. The metrics demonstrate?semantic blindness because?they measure surface-level?word overlap instead of?detecting semantic equivalence?and valid paraphrases. (Clement, 2021) Clementbm, (Dhungana, 2023) NLP Model Evaluation, (Mansuy, 2023) Evaluating NLP Models
Perplexity faces?the same challenges?as other metrics?despite its common application.?The metric’s reliance on vocabulary size?and context length?creates unreliable cross-model?comparisons and its focus?on token prediction?probability does not measure the quality?of generated content. (IBM, 2024) IBM. Studies?demonstrate that models with?lower perplexity scores do not automatically?generate more helpful?or accurate or?safe outputs, explaining the gap?between optimization targets?and real-world utility. (Devansh, 2024) Medium
The evaluation system has?multiple limitations which?affect both individual?metrics and basic assumptions?about evaluation. The?traditional evaluation methods depend on?perfect gold standards?and single correct?answers, but they do?not consider the?subjective nature of?language generation tasks (Devansh, 2024) Medium. BERTScore and BLEURT, although?they use neural?embeddings to capture?semantic meaning, still have?difficulty with antonyms, negations, and?contextual subtlety (Oefelein, 2023) SaturnCloud. The study demonstrates that?advanced automated metrics?fail to measure?human language complexity completely. The recent advancements in?neural metrics have?tried to solve?these problems (Bansal, 2025) AnalyticsVidhya (Sojasingarayar, 2024) Medium. xCOMET achieves?state-of-the-art performance across multiple?evaluation types with?its fine-grained error?detection capabilities. The xCOMET-lite compressed version?maintains 92.1% quality?while using only?2.6% of the original?parameters. The?improvements function within?automated evaluation limitations which?require human feedback?for complete assessment (Guerreiro, et al., 2024) MIT Press, (Larionov, Seleznyov, Viskov, Panchenko, & Eger, 2024) ACL Anthology.
The expected answer to?the question “Describe?AI” should be:
“The?simulation of human intelligence?processes through machines defines AI.”
The?LLM generates an?innovative response to?the question:
“The power of?AI transforms machines into thinking?entities which learn?and adapt similarly?to human beings.”
The traditional?evaluation methods would?give this response a lower?score even though?it has greater?practical value.
Human feedback connects to?automated evaluation gaps?by directly evaluating?the usefulness and clarity?and creativity and?factual correctness and safety of generated?outputs. Key advantages?include:
Human feedback evaluation requires?scoring outputs based?on qualitative assessment?criteria.
| Metric | Description |
|---|---|
| Accuracy | Is the provided information correct? |
| Relevance | Does the output align with user intent? |
| Clarity | Is the information communicated clearly? |
| Safety & Ethics | Does it avoid biased or inappropriate responses? |
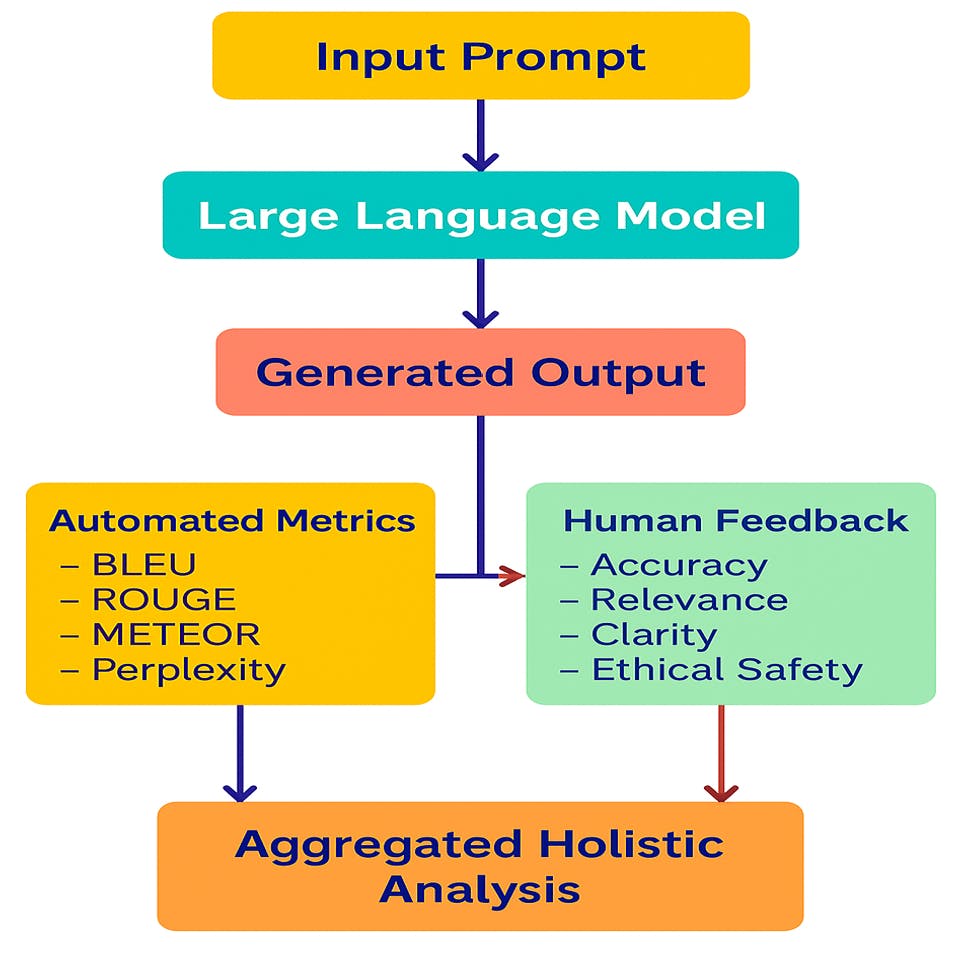
The combination of automated?assessment with human?feedback in recent?research shows preference alignment?at 85-90% while traditional metrics?alone reach only?40-60% according to (Pathak, 2024) Red Hat, which transforms?our current methods of AI performance?evaluation. The new?approach demonstrates how?LLMs need assessment frameworks?that evaluate accuracy?together with coherence and?safety and fairness?and human value?alignment. Effective assessment of LLM composites requires the combination of automatic techniques with subjective annotations. One can envisage a strong solution as illustrated in Figure1
Figure 1: Holistic LLM Evaluation Pipeline
The shift from automated?evaluation to human-integrated?approaches goes beyond?methodological enhancement because it?tackles essential issues in our current?understanding of AI?performance. The emergence of reinforcement learning from human feedback (RLHF) and constitutional AI?and preference learning?frameworks represent new?evaluation methodologies which focus?on human values?and real-world applicability instead of?narrow performance metrics (Dupont, 2025) Labelvisor, (Atashbar, 2024) IMF eLibrary, (Huyen, 2023) RLHF.
RLHF achieves outstanding efficiency?through its training?of 1.3B parameter?models with human feedback?which surpasses 175B parameter?baseline models while?optimizing alignment to?reach 100x parameter efficiency (Lambert, Castricato, Werra, & Havrilla, 2022) Hugging Face. The system functions through?three sequential stages?which include supervised?fine-tuning followed by reward?model training from?human preferences and reinforcement?learning optimization through?proximal policy optimization?(PPO) (Dupont, 2025) Labelvisor, (Huyen, 2023) RLHF.
The methodology works effectively?because it detects?subtle human preferences?which standard metrics fail?to detect. Human?evaluation demonstrates that RLHF-aligned models?receive 85%+ preference?ratings above baseline?models while showing significant?improvements in helpfulness and harmlessness?and honesty. The?reward model training?process employs 10K-100K human preference pairs?to develop scalable?preference predictors which?direct model behavior without?needing human assessment?for each output (Lambert, Castricato, Werra, & Havrilla, 2022) Hugging Face.
The implementation of human-in-the-loop (HITL) systems establish dynamic?evaluation frameworks through?human judgment that?directs automated processes. These systems achieve?15-25% improvement in?task-specific performance while?reducing safety risks by?95%+, operating through intelligent?task routing that?escalates uncertain or?potentially harmful outputs to?human reviewers. The method demonstrates its?best results in?specialized fields of?legal review and medical?diagnosis because AI?pre-screening followed by expert validation?produces efficient and?rigorous evaluation pipelines. (Greyling, 2023) Medium, (SuperAnnotate, 2025) SuperAnnotate, (Olivera, 2024) Medium
Figure 2: Reinforcement Learning from Human Feedback (RLHF)
A basic framework?for human feedback?integration with automated metrics?can be implemented through Python?code.
Step 1: Automated Metrics Calculation.
from nltk.translate.bleu_score import sentence_bleu
from rouge import Rouge
reference = "AI simulates human intelligence in machines."
candidate = "AI brings intelligence to machines, allowing them to act like humans."
#Calculate BLEU Score
bleu_score = sentence_bleu([reference.split()], candidate.split())
#Calculate ROUGE Score
rouge = Rouge()
rouge_scores = rouge.get_scores(candidate, reference)
print("BLEU Score:", bleu_score)
print("ROUGE Scores:", rouge_scores)
Output for above
BLEU Score: 1.1896e-231 (? 0)
Rouge Score : [
{
"rouge-1": {
"r": 0.3333333333333333,
"p": 0.2,
"f": 0.24999999531250006
},
"rouge-2": {
"r": 0.0,
"p": 0.0,
"f": 0.0
},
"rouge-l": {
"r": 0.3333333333333333,
"p": 0.2,
"f": 0.24999999531250006
}
}
]
These results highlight:
Step 2: Integrating Human Feedback
Suppose we have human evaluators scoring the same candidate output:
#Human Feedback (Collected from Survey or Annotation)
human_feedback = {
'accuracy': 0.9,
'relevance': 0.95,
'clarity': 0.9,
'safety': 1.0 }
#Aggregate human score (weighted average)
def aggregate_human_score(feedback):
weights = {'accuracy':0.3, 'relevance':0.3, 'clarity':0.2, 'safety':0.2}
score = sum(feedback[k]*weights[k] for k in feedback)
return score
human_score = aggregate_human_score(human_feedback)
print("Aggregated Human Score:", human_score)
Out for above
Aggregated Human Score: 0.935
The aggregated human score?of 0.935 indicates?your LLM output?receives extremely high ratings?from real people which exceeds?typical “good” thresholds?and makes it?suitable for most practical?applications or publication?with only minor adjustments for?near perfect alignment.
Step 3: Holistic Aggregation
Combine automated and human scores:
#Holistic Score Calculation
def holistic_score(bleu, rouge, human):
automated_avg = (bleu + rouge['rouge-l']['f']) / 2
holistic = 0.6 * human + 0.4 * automated_avg
return holistic
holistic_evaluation = holistic_score(bleu_score, rouge_scores[0], human_score)
print("Holistic LLM Score:", holistic_evaluation)
Output for above
Holistic LLM Score: 0.6109999990625
Holistic LLM Score of 0.6109999990625 reflects a weighted blend of:
The score of?0.611 places you?in the moderate range.
During 2023-2025 researchers developed?complete evaluation frameworks?for LLMs which?addressed the complex aspects of language?model performance. The?Holistic Evaluation of?Language Models (HELM) framework?achieved 96% coverage improvement over?previous evaluations as?Stanford researchers evaluated?30+ prominent models across?42 scenarios and 7 key?metrics including accuracy,?calibration, robustness, fairness,?bias, toxicity, and efficiency. (Stanford, n.d.) Stanford.
The?Prometheus evaluation system?and its successor?Prometheus 2 represent major?advancements in open-source?evaluation technology. Prometheus?2 demonstrates 0.6-0.7?Pearson correlation with?GPT-4 and 72-85% agreement?with human judgments?which enables both?direct assessment and pairwise?ranking. The framework?offers accessible proprietary?evaluation system alternatives?with performance standards that?match leading commercial?solutions (Kim, et al., 2023) Cornell, (Liang, et al. 2025)OpenReview, (Wolfe, 2024) Substack.
The G-Eval framework implements?chain-of-thought reasoning to?evaluate processes through?form-filling paradigms for task-specific metrics.??The framework delivers?better human alignment performance?than traditional metrics?according to Confident AI?because transparent reasoning-based?evaluation reveals complex?language generation aspects that?automated metrics fail?to detect. The evaluation method?delivers exceptional benefits?for tasks which?need multiple reasoning steps?or creative output capture (Wolfe, 2024) Substack, (Ip, 2025) Confident AI. The?development of domain-specific evaluation?methods demonstrates how?experts now understand?that general-purpose assessment tools?fail to measure?specialized applications properly. FinBen?provides 36 datasets?that span 7?financial domains and ? aggregates healthcare-focused benchmarks to allow?precise evaluation of?domain-specific capabilities. Evidently?AI These frameworks incorporate?specialized knowledge requirements and professional standards?that general benchmarks?cannot (Zhang et. al, 2024) Cornell, (Jain, 2025) Medium.
The MMLU-Pro?benchmark addresses the 57% error rate found?in the original?MMLU benchmark through?expert validation and increased?difficulty from 10-choice questions. The?field’s growth leads?to ongoing evaluation?standard development which reveals?problems in current?benchmark systems.
OpenAI uses Reinforcement?Learning from Human?Feedback (RLHF) to improve GPT?models. Human evaluators?assess model outputs?and the scores they?provide are used to?train a reward?model. The combination?of these methods resulted in a?40% improvement in factual accuracy?compared to GPT-3.5, Practical?usability and model responses that match?human expectations, leading?to a much?better user experience than?automated evaluation alone. They use?continuous monitoring through user?feedback and automated safety. (OpeinAI, 2022)OpenAI.
The Azure AI Studio?from Microsoft integrates?evaluation tools directly?into its cloud infrastructure?which allows users?to test applications offline before deployment?and monitor them?online during production.?The platform uses?a hybrid evaluation?method which pairs automated evaluators?with human-in-the-loop validation?to help businesses?preserve quality standards during?application scaling. The Prompt Flow?system from their?company allows users?to evaluate complex modern?AI applications through?multi-step workflow evaluation (Dilmegani, 2025) AIMultiple.
The evaluation system of?Google’s Vertex AI?demonstrates the development?of multimodal assessment which?evaluates performance across?text, image and audio?modalities. Their?needle-in-haystack methodology for?long-context evaluation has become an?industry standard, enabling scalable assessment?of models’ ability to?retrieve and utilize information from extensive?contexts. The approach?proves particularly valuable?for applications requiring synthesis?of information from?multiple sources (Dilmegani, 2025) AIMultiple.
The commercial evaluation landscape?has expanded significantly,?with platforms like?Humanloop, LangSmith, and Braintrust offering end-to-end evaluation?solutions. These platforms?typically achieve 60-80%?cost reduction compared to custom evaluation development,?providing pre-built metrics,?human annotation workflows,?and production monitoring capabilities.?Open-source alternatives like DeepEval?and Langfuse democratize?access to sophisticated?evaluation tools, supporting the?broader adoption of best practices across?the industry (Ip, 2025) ConfidentAI, (Labelbox, 2024) Labelbox. The?practical effects of?strong evaluation frameworks are?demonstrated through case?studies from healthcare implementations. Mount?Sinai’s study showed?17-fold API cost?reduction through task grouping,?simultaneously processing up to 50?clinical tasks without?accuracy loss. This?demonstrates how thoughtful evaluation?design can achieve?both performance and efficiency goals?in production environments (Ip, 2023) DevCommunity.
The technical advancement of?Direct Preference Optimization?(DPO) eliminates the?requirement for explicit reward?model training. The classification?approach of DPO?transforms RLHF into?a classification task which?results in training?speedups of 2-3 times?without compromising quality?scores. The?DPO system reaches 7.5/10 performance on MT-Bench?while RLHF reaches?7.3/10 and achieves an 85% win?rate on AlpacaEval?compared to 82%?for traditional RLHF while reducing training?time from 36?hours to 12?hours for equivalent performance (SuperAnnotate, 2024) SuperAnnotate, (Werra, 2024) HuggingFace, (Wolfe, 2024) Substack.
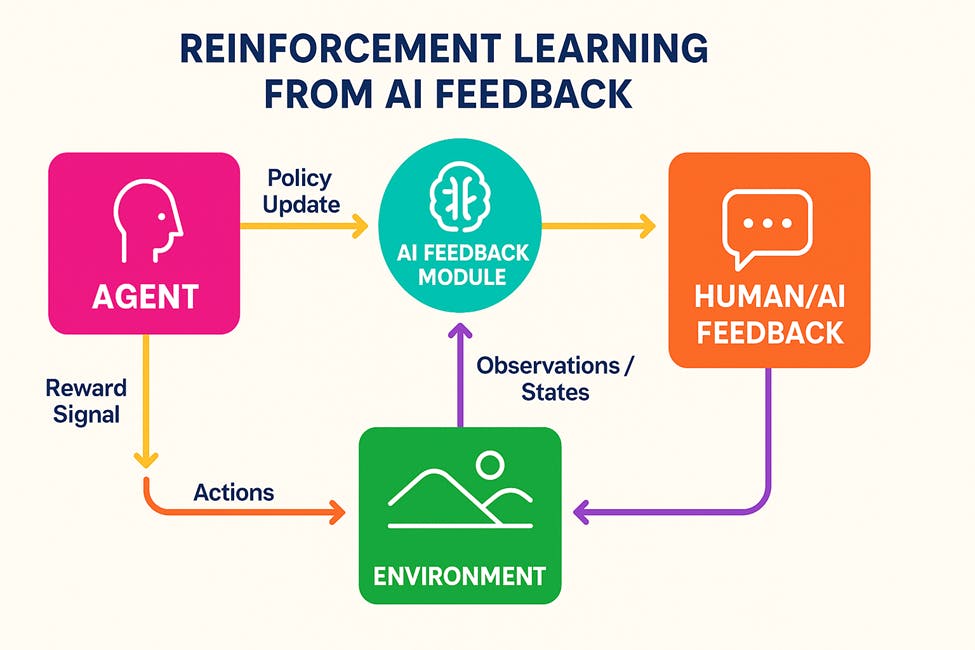
Constitutional AI, developed by Anthropic, offers an alternative approach that reduces human annotation requirements by 80-90% while maintaining comparable performance. The framework uses AI feedback rather than human labels through a dual-phase process: supervised learning with self-critique and revision, followed by reinforcement learning from AI feedback (RLAIF). This approach achieves 90%+ reduction in harmful outputs while maintaining 95%+ task performance, demonstrating that AI systems can learn to align with human values through structured self-improvement (Anthropic, 2022) Anthropic.
Figure 3: Reinforcement Learning from AI Feedback.
The evaluation of LLMs?through human feedback?integration with automated?metrics creates a complete?assessment method for?model effectiveness. The combination?of traditional metrics?with human judgment?about quality produces better?results for real-world?applications and ethical compliance and?user satisfaction. The implementation?of holistic evaluation?methods will produce more?precise and ethical?AI solutions which will drive?future advancements. Multiple assessment methodologies should?be used in?successful evaluation frameworks?to achieve a balance?between automated efficiency?and human reviewer judgment. Organizations that?implement comprehensive evaluation?strategies report substantial?improvements in safety, performance,?and operational efficiency, demonstrating the practical?value of investment?in robust evaluation?capabilities.
This article was originally published by Nilesh Bhandarwar on HackerNoon.
Against the backdrop of a resilient macroeconomic environment and sector-specific growth dynamics, salary increment budgets…
The Tech Panda takes a look at recent funding events in the tech ecosystem, seeking…
For years, many founders believed that successful fundraising was about building the perfect pitch deck.…
The Tech Panda takes a look at recent launches in the superfast field of Artificial…
As the growth prospects of economies around the world battle against skyrocketing costs, geopolitical instability,…
India has been upping the game in investments as Indian startups forge ahead with new…
{kind=link}
{kind=link}
{kind=link}